
Stream: bulk data
Topic: Bulk Data Upload
 Grahame Grieve (Feb 26 2019 at 04:56):
Grahame Grieve (Feb 26 2019 at 04:56):
I'm chatting with a vendor about uploading bulk data. They would like to know how we would recommend uploading the results of a bulk data query to their own FHIR server .
Grahame Grieve (Feb 26 2019 at 04:56):
here's my thoughts:
Josh Mandel (Feb 26 2019 at 04:57):
(we're also planning to define an $import operation this spring)
Josh Mandel (Feb 26 2019 at 04:58):
Would love your thoughts!
Grahame Grieve (Feb 26 2019 at 04:58):
Post the nd-json files, one at a time to [base], the base URL for the service, with a mime type of application/fhir+ndjson, and the server automatically treats this is a batch operation to upload the resources in the nd-json file
Grahame Grieve (Feb 26 2019 at 04:58):
this is less than the $import operation we've previously talked about, but very simple to get going with.
Josh Mandel (Feb 26 2019 at 05:00):
If we're talking about net new server behavior, might be more robust to post something like the full status response so the server can process files in the background ... But sure, if processing full ndjson files synchronously is feasible for this server, I'd say go for it.
Lloyd McKenzie (Feb 26 2019 at 05:01):
How would that work if there are references between some of the resources - e.g. a Patient pointing to Organization
Josh Mandel (Feb 26 2019 at 05:01):
Uploading large files can be a pain because (as far as I know) there's no good standardized resume approach. (Is there?)
Grahame Grieve (Feb 26 2019 at 05:02):
upload - would have to accept broken links. resume - not catering for that in this simple API
Lloyd McKenzie (Feb 26 2019 at 05:03):
Accept them, sure. But would it repair them as other resources are loaded?
Lloyd McKenzie (Feb 26 2019 at 05:03):
If it keeps the original ids, that's easy. But if it changes them, there'd be update work involved
Josh Mandel (Feb 26 2019 at 05:03):
Makes sense. You could also just have the client turn ndjson files into bundles (can be done in a streaming fashion even) so the server doesn't need special behavior
Josh Mandel (Feb 26 2019 at 05:04):
If synchronous upload and one file at a time and suspended referential integrity checks are all okay.
Grahame Grieve (Feb 26 2019 at 06:02):
you could also just have the client turn ndjson files into bundles
yes, you could. Not really consistent with our general philosophy of shoving work to the server where it's convenient
Brian Postlethwaite (Feb 26 2019 at 08:20):
Could we post the export status result, then let the server manage the rest?
Brian Postlethwaite (Feb 26 2019 at 08:21):
Grabbing the large binaries as it can.
Brian Postlethwaite (Feb 26 2019 at 08:23):
Not a fan of the post ndjson to the root... The size of these files is likely larger than post can handle.
Brian Postlethwaite (Feb 26 2019 at 08:25):
And status and delete processing could work the same as export.
nicola (RIO/SS) (Feb 26 2019 at 08:26):
My research in uploading large files was dissapointing. There is no good way (most of services like dropbox, s3 just split and upload in chunks). Even streaming http working only for download. We can turn upload into download pointing server to download api?
Brian Postlethwaite (Feb 26 2019 at 08:29):
My suggestion was to post the final output of the export to the import.
nicola (RIO/SS) (Feb 26 2019 at 08:37):
Another option is use web sockets channel - but it does not look resty :)
Grahame Grieve (Feb 26 2019 at 14:03):
What’s the limit on post size? I don’t have any limits....
Josh Mandel (Feb 26 2019 at 14:06):
you could also just have the client turn ndjson files into bundles
yes, you could. Not really consistent with our general philosophy of shoving work to the server where it's convenient
The context for this discussion was, I thought, a simple stopgap -- before we define an import operation. But if your client only needs to work with one server and that server developer is willing to do the work, then by all means :-)
nicola (RIO/SS) (Feb 26 2019 at 18:00):
@Grahame Grieve it is usually limited by your web server implementation, memory buffers and disk cache and all proxies on the way. In google cloud or aws if i’m not wrong - max size is about 4g, but real chunks sent by official sdk are much smaller.
nicola (RIO/SS) (Feb 26 2019 at 18:06):
For downloading you can use https://ru.wikipedia.org/wiki/Chunked_transfer_encoding and be memory efficient with ndjson processing data in a stream.
nicola (RIO/SS) (Feb 26 2019 at 18:09):
But this protocol almost not supported by HTTP client libraries for uploading.
nicola (RIO/SS) (Feb 26 2019 at 18:10):
Potentially we can open web socket and stream data with back pressure and some type of cursor to restore upload in a specific position, but this is not REST at all :(
nicola (RIO/SS) (Feb 26 2019 at 18:13):
Databases replicate data thro socket connection or by producing chunks of replication log as small files indexed by counter - pasted image http://1.bp.blogspot.com/_26KnjtB2MFo/SYVDrEr1HXI/AAAAAAAAAEY/ncq_AW-Vv-w/s320/pg_warm_standby.png

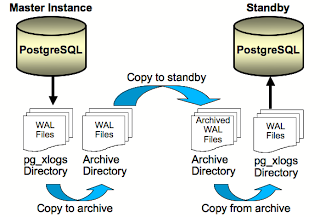
nicola (RIO/SS) (Feb 26 2019 at 18:16):
https://gist.github.com/niquola/2bf49e7c9119c425261389e3a7a3d1d3 here is my notes from amsterdam discussion
Brian Postlethwaite (Feb 26 2019 at 19:49):
Usually a setting in iis, and default isn't that big, nowhere near gigabytes that I've experienced. That's where compression denial of service attacks go. I'll try dig out the setting I use in .Net to make it bigger (to 4mb I think I made it so larger codesystems can be loaded)
Michael Hansen (Feb 27 2019 at 02:45):
In my opinion uploading the files directly through the API doesn't seem practical except in use cases where the amount of data is very small. In those cases batch bundles seem to be a better option. Giving the server something like the result of an export (with a list of files) seems more practical.
Grahame Grieve (Mar 03 2019 at 19:40):
indeed. but we were looking for a stop gap measure
Josh Mandel (Mar 03 2019 at 20:08):
(for stop gap, I still think I'd just have the client produce a normal, compliant bundle)
Paul Church (Mar 18 2019 at 19:56):
We have been experimenting with bulk import in Google Cloud quite a bit. I'll start a separate thread with some lessons learned for the general case. For the stopgap case, you can do a lot with batch/transaction bundles if the client does the preprocessing.
We wrote some client code that walks a set of input files, parses resources, constructs the reference graph, does reference tiering, and produces a sequence of transaction bundles that can be executed in sequential order to accomplish the import while preserving referential integrity at every point. There is some risk that the data could have reference cycles too large to post as a bundle and/or to execute in a single transaction, but that's pretty unlikely in our experience. In practice this has been quite successful at getting data in, at the cost of some heavy lifting on the client side.
I'm bringing this up partly just to agree with what has already been said above, but also because referential integrity and bundle semantics are a major challenge in defining the general $import operation.
Grahame Grieve (Mar 18 2019 at 20:01):
how have you handled circular dependencies?
Paul Church (Mar 18 2019 at 21:08):
Put the whole cycle in a single bundle. As part of the transaction, the bundle's local references will either remain intact (for PUT) or get rewritten to server-assigned IDs (for POST).
Last updated: Apr 12 2022 at 19:14 UTC